

菜菜不是虚名,是真的菜,所以发布的文章不是“教你做什么”,而是“我正在做什么”。如果恰好这个阶段你也正在玩这些,可能帮你节省一点时间,或者避开一两个小坑,仅此而已。
今天起会发布一些DeepSeek相关的小文章,也是因为我最近在倒腾这玩意。
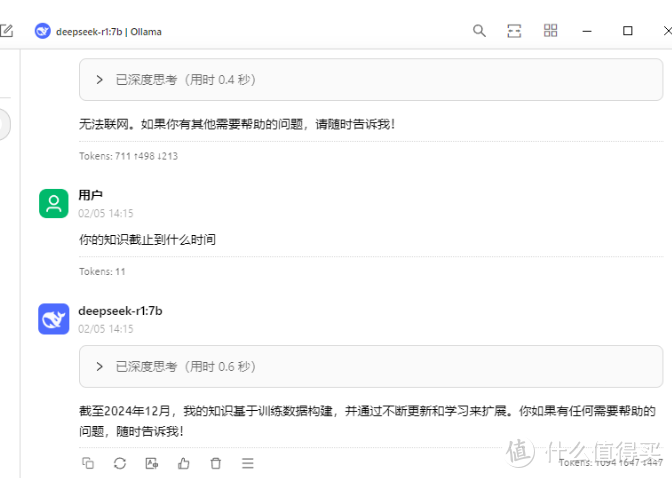

问题一:刷短视频和看文章,貌似DeepSeek经受了一系列的网络攻击后,大家都部署了本地的DeepSeek R1,难道是比DeepSeek的APP不好用吗?
我的认识是这样的,我们个人用户,偶尔打开提问求答案这种简单的需求,DeepSeek 的APP几乎都能100%的满足。毕竟一天也用不到几次。
但是这两类用户对DeepSeek这种Ai有强烈的需求和个性化的需求,一是每天8个小时工作内容里,有一半以上时间需要借助DeepSeek来完成和解决问题。本地部署能够确保顺利完成工作内容。
另外全球范围内的科技巨头和大型的集团公司普遍宣布已经接入DeepSeek,有些本身就是云服务提供商,它们有强大的硬件支撑,能够为客户提供最新的最有价值的服务,并且按分钟计费!另外一些则是本地化后进一步训练来服务自己的行业和集团,这就是Ai在不同行业发挥的作用。
而个人部署DeepSeek R1的某个版本,不单单是为了和Ai聊个天,而是在其基础上,进一步训练,使这个DeepSeek能够了解自己的行业,服务自己的领域,完成独特的工作。
问题二:DeepSeek R1和DeepSeek V3的区别,以及DeepSeek R1 的1.5b到671b的区别?
如果我们使用DeepSeek的APP对话,其实使用的是DeepSeek V3,它有671b的总参数,也有叫它满血版。零散的使用,用它最聪明!
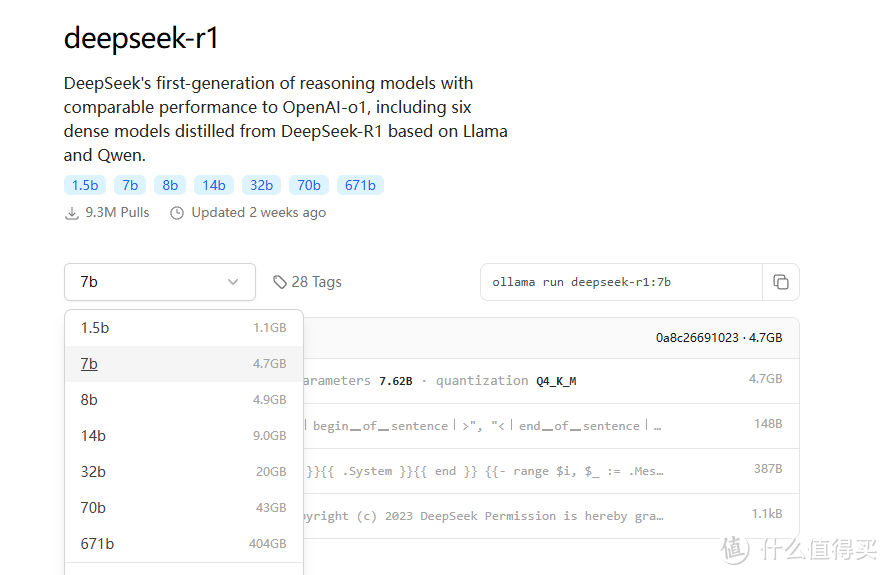
DeepSeek R1是DeepSeek公司推出的一款开源推理模型,并且又“蒸馏”出6个小模型,就是大家知道的1.5b,7b,8b,14b,32b,70b。这其中就有两个字眼: Llama 和 Qwen 。1.5b和7b,14b,32b是DeepSeek-R1-Distill-Qwen-7B这样的名称。8b和70b是DeepSeek-R1-Distill-Llama-8B这样的名称。
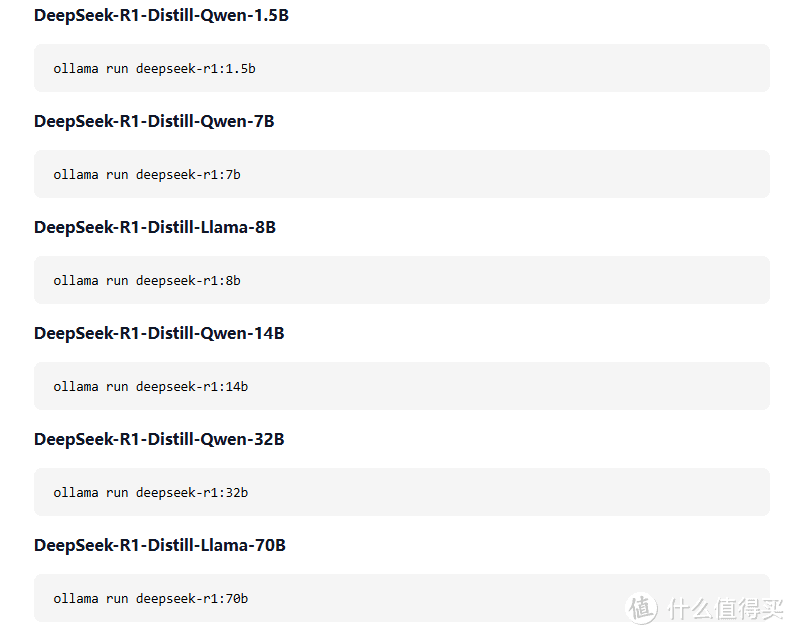
所以,如果你要本地部署,选哪个“蒸馏”版本,第一依据是自己的硬件,你有多大的显卡,多大的内存,这个网上很多说法,你可以做个衡量,我2060的显卡6G显存,32G内存,正在用7b,思考很快,输出流畅。
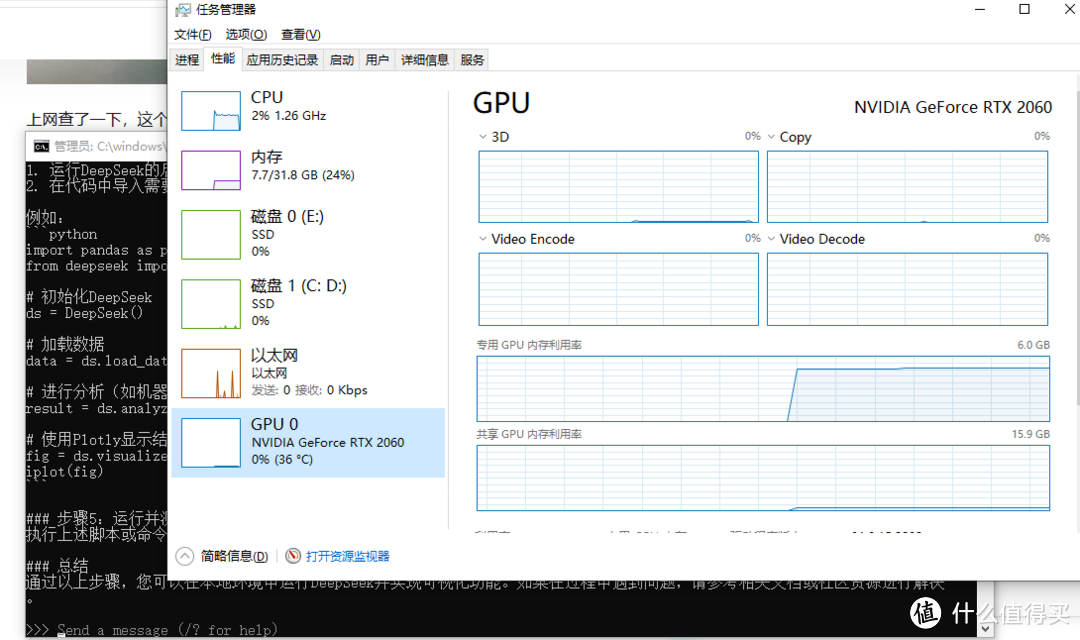
选择哪个版本第二个依据是看Llama 和 Qwen的区别。
问题三:本地部署8GB显存,选择7b还是8b?
Qwen是由阿里巴巴达摩院推出的,主要服务于中文和全球市场,特别优化了中文语料和应用。LLaMA是由Meta AI(前Facebook)开发的,主要针对学术研究和开源领域,提供参数规模较小但性能强大的模型。
Qwen特别专注于中文优化。LLaMA是一个通用模型,主要使用英语语料进行训练。所以,参考了一些信息后,非得从7b和8b这两个中选择的话。基于Qwen的DeepSeek-R1-Distill-Qwen-7B可能更合适。
问题四:怎么本地部署DeepSeek R1?
网上铺天盖地的教程,很详细,也很简单,你搜索下照着做就能完成。
大体的思路是先装Ollama,Ollama是一个用于在本地运行大型语言模型的工具。然后在Ollama里用明令行拉取和运行DeepSeek R1的某个版本。成功后在命令行里就能“聊天”。但到这里才是“毛坯房”。更好的使用起码得个可视化的工具(有四五个可选),想要训练的更符合你的需求,也需要额外的工具支持。
稍后陆续分享,欢迎进一步交流。